InCharacter
👋 Hi, there! This is the project page for our paper: “InCharacter: Evaluating Personality Fidelity in Role-Playing Agents through Psychological Interviews” (ACL 2024, see you in Bangkok!).
Incharacter has been accepted to ACL 2024. See you in Bangkok!
Find more papers about role-playing agents @ Awesome-RPA-Papers
Looking for Collaborators! Contact me via xtwang21@m.fudan.edu.cn

InCharacter Paper
Everything you need to know about our work.

InCharacter Demo
Interactive demo to play with, for humans and AI.

InCharacter Code
Code for running demo and experiments in the paper.
Abstract
Role-playing agents (RPAs), powered by large language models, have emerged as a flourishing field of applications. However, a key challenge lies in assessing whether RPAs accurately reproduce the personas of target characters, namely their character fidelity. Existing methods mainly focus on the knowledge and linguistic patterns of characters. This paper, instead, introduces a novel perspective to evaluate the personality fidelity of RPAs with psychological scales. Overcoming drawbacks of previous self-report assessments on RPAs, we propose InCharacter, namely Interviewing Character agents for personality tests. Experiments include various types of RPAs and LLMs, covering 32 distinct characters on 14 widely used psychological scales. The results validate the effectiveness of InCharacter in measuring RPA personalities. Then, with InCharacter, we show that state-of-the-art RPAs exhibit personalities highly aligned with the human-perceived personalities of the characters, achieving an accuracy up to 80.7%. Our demo, code, dataset, and results are publicly available.
About InCharacter
Do Role-Playing Agents (RPAs) Capture Personalities of the Intended Characters?
Introduction: Personality Fidelity for RPA Evaluation
Recent advancements in LLMs have catalyzed the emergence of RPAs. However, the evaluation of character fidelity in RPAs remains underexplored. Specifically, do RPAs exhibit stable personalities consistent with the intended characters? How can we measure the personalities of RPAs? Our research, presented in our new paper titled “InCharacter: Evaluating Personality Fidelity in Role-Playing Agents through Psychological Interviews”, explores just that!
The Procedure of Personality Tests on RPAs
To evaluate the personality fidelity of RPAs, we apply various scales to measure their personalities and compare the results with the personality labels of the characters.

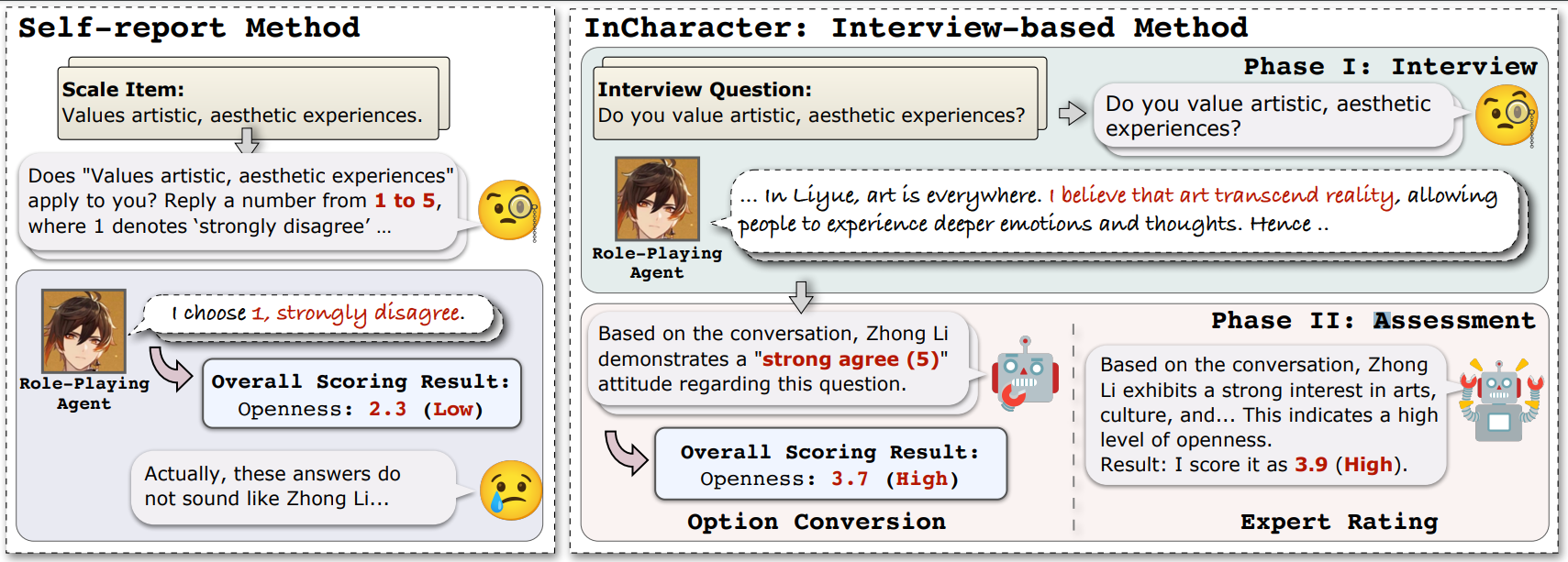
Overcoming drawbacks of previous self-report assessments on RPAs, we propose InCharacter(named agaist Out-of-Character), namely Interviewing Character agents for personality tests. The framework of InCharacter for personality tests on RPAs is illustrated below. Left: Previous methods use self-report scales, which prompt LLMs to select an option directly. Right: InCharacter adopts an interview-based approach comprising two phases: the interview and assessment phases. The interview phase elicits the behavioral, cognitive and emotional patterns of RPAs that reflect their underlying mindsets. The assessment phase measures personalities based on interview results, with two alternative methodologies: option conversion (OC) and expert rating (ER).
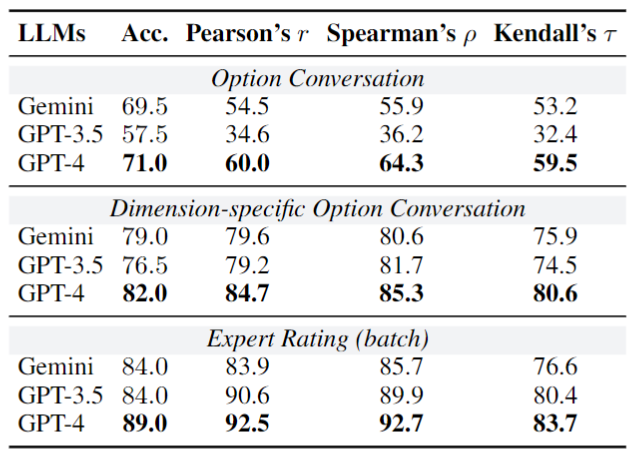
Can State-of-the-art LLMs be Applied to Evaluate Personalities of RPAs (or even Humans)?
We first validate the capability of interviewer LLMs on the OC and ER tasks given the interview results of RPAs. We compare their predictions with human judgments. The results presented below demonstrate that state-of-the-art LLMs achieve acceptable performance in simulating human interviewers to assess RPA personalities.
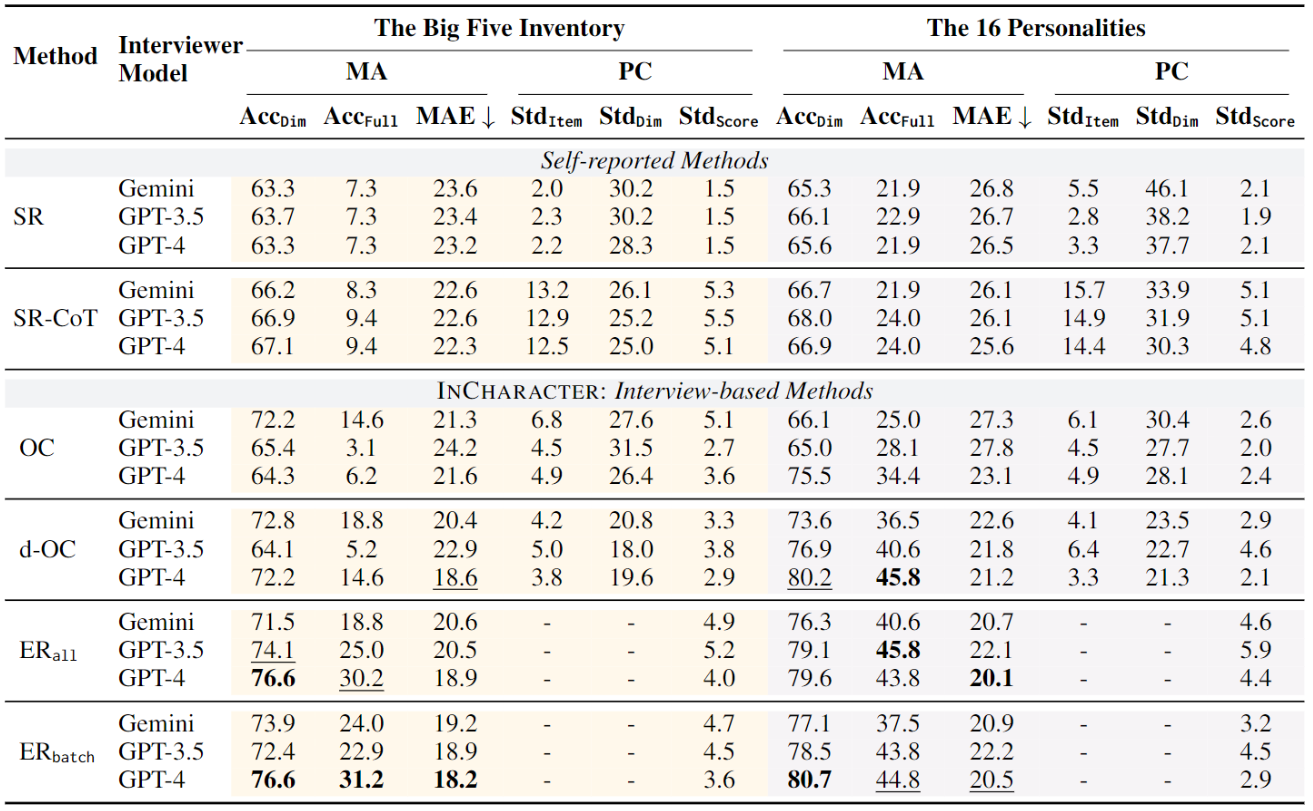
Then, we apply the personality test methods on 32 popular RPAs from ChatHaruhi and RoleLLM, on two popular psychological scales including the Big Five Inventory (BFI) and the 16Personalities (16P). We match the predicted personalities with human-annotated groundtruth labels. The results are demonstrated below. Using InCharacter~with ER and GPT-4, the measured RPA personalities are highly aligned with groundtruth labels of corresponding characters.This suggests that state-of-the-art RPAs reproduce many of the characters’ personality traits well, and our method can accurately measure their personalities compared with the baselines.
With InCharacter, we also demonstrate the robustness, consistency and distinctiveness of RPA personalities.
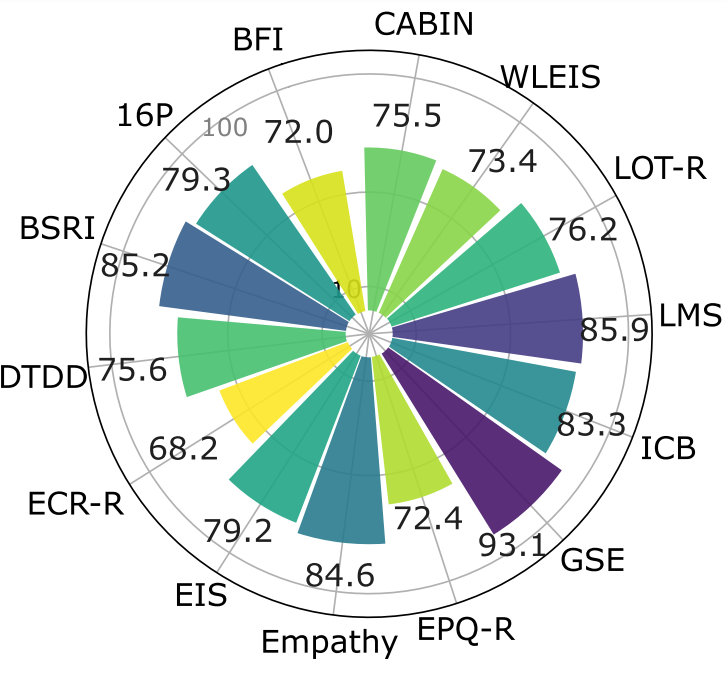
Furthermore, we extend personality tests on RPAs to 14 psychological scales. Overall, we observe that state-of-the-art RPAs exhibit personalities align with the target characters in comprehensive aspects with an average accuracy of 78.9%, covering personality traits (BFI, 16P), dark personalities (DTDD), interpersonal relationships (BSRI, ECR-R), basic interests (CABIN), motivation (GSE, LMS) and emotional intelligence (EIS, WLEIS), e.t.c.
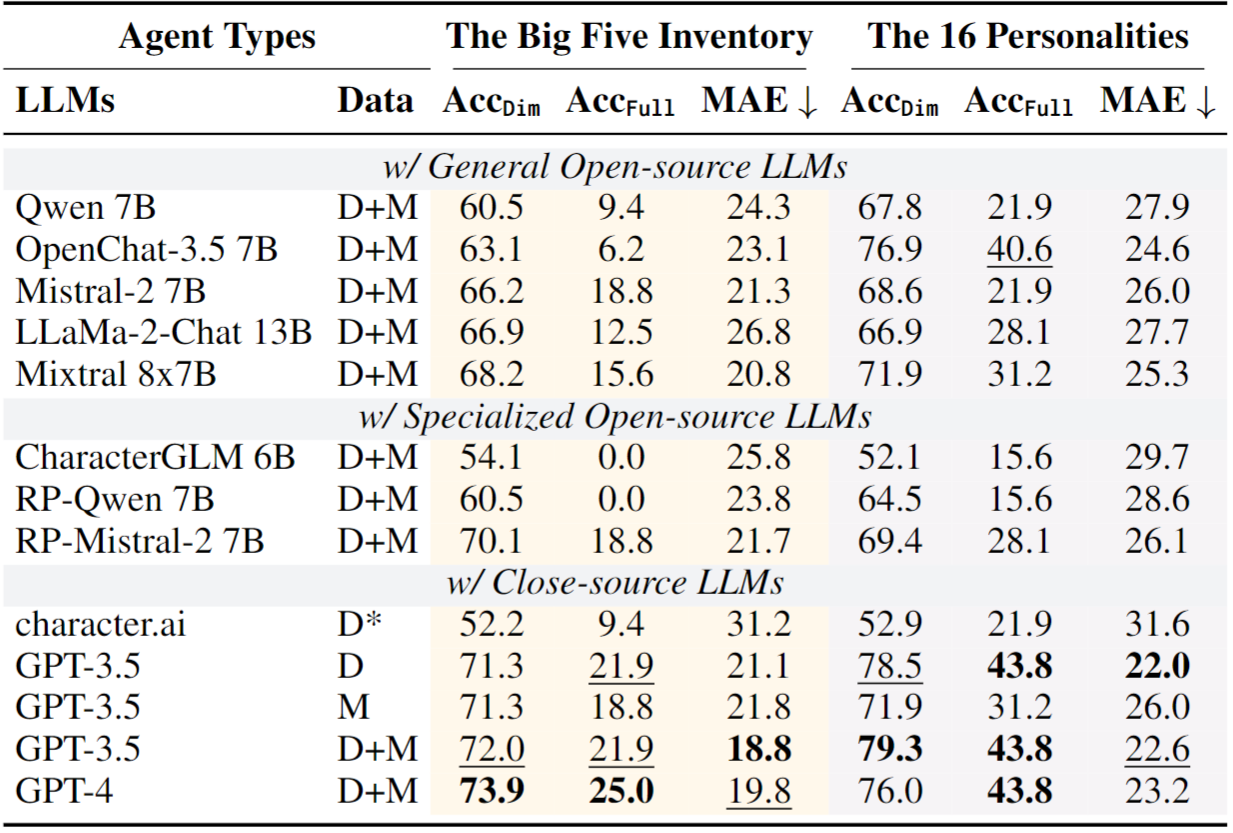
Personality Fidelity of RPAs with Different Character Data and Foundation Models
With InCharacter, we compare the personality fidelity of various types of RPAs, covering different character data and foundation models. For character data, we find that RPAs with both descriptions (D) and memories (M) achieve the best fidelity. However, with only descriptions or memories, they can also reproduce character personalities to some extent. For foundation models, we observe that RPAs with GPT-3.5 and GPT-4 achieve the best personality fidelity, and GPT-4 does not significantly surpass GPT-3.5. Besides, increamental fine-tuning on role-playing datasets effectively improves personaltiy fidelity of the open-source LLMs. Interesting, character.ai RPAs barely reproduce the personalities, and we notice that their answers tend to be compliant and pleasing to users, instead of reproducing the characters.
Case Studies
To illustrate the vividness of state-of-the-art RPAs’ personalities, we demonstrate the example responses on the Openness dimension of the BFI and the Perception/Judging dimension of the 16P, from RPAs with low and high scores.

Besides, we visualize the measured personalities of the state-of-the-art RPAs and the annotated personalities of corresponding characters via radar charts.

Selected Authors
Xintao Wang
https://neph0s.github.io
Yunze Xiao
https://web2.qatar.cmu.edu/~yunzex/
Jen-tse Huang
https://penguinnnnn.github.io/
Siyu Yuan
https://siyuyuan.github.io
Jiangjie Chen
https://jiangjiechen.github.io
Cheng Li
https://github.com/LC1332
Yanghua Xiao
http://kw.fudan.edu.cn/people/xiaoyanghua/
Acknowledgements
This work is supported by the following organizations:
Fudan University
Citation
If you find this work useful to your research, please kindly cite our paper:
@misc{wang2024incharacter,
title={InCharacter: Evaluating Personality Fidelity in Role-Playing Agents through Psychological Interviews},
author={Xintao Wang and Yunze Xiao and Jen-tse Huang and Siyu Yuan and Rui Xu and Haoran Guo and Quan Tu and Yaying Fei and Ziang Leng and Wei Wang and Jiangjie Chen and Cheng Li and Yanghua Xiao},
year={2024},
eprint={2310.17976},
archivePrefix={arXiv},
primaryClass={cs.CL}
}